
– W. Edwards Deming
I had to write a 750-word limit essay for my English 101 class at Saint Thomas University in Miami on the meaning of God. I wrote, “God can’t be limited to 750 words so if I start, I will not be able to meet this requirement.” I got an A on the paper. However, data can be limited, understood, exposed, and free from using blind faith. If we want to get the full potential and power of data, we must demystify it!
The average adult makes over 30,000 decisions per day and with the “promise” of controlled access to democratized data available to the masses – the hunger to harness its power to help automate the exponential growth of these decisions is addictive. So addictive that McKinsey’s 2010 report estimates that the manufacturing sector alone produced 1800 petabytes of data and that is before the surge in machine sensors. (see figure 1.1)
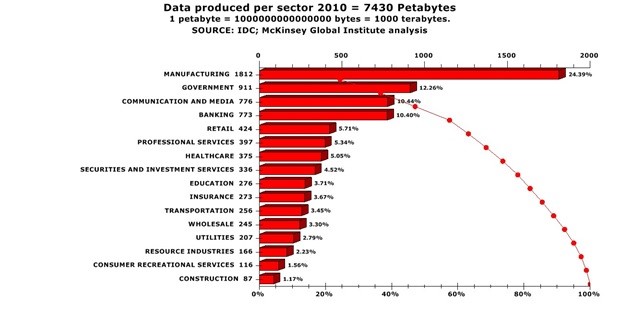 Figure 1.1
Figure 1.1
So we are making more decisions and producing more data but is that helping? The simple answer is, no.
Tom Redman, a leading expert on data quality, suggests that only 3% of all data are fit for use – Redman defines this as “defect-free and possesses the desired features for the intended use.” If we want data to help us make decisions, we need better data!
Here are four ways to get better data:
- Sample your current data for quality. We audit product and service quality all of the time. How often has a customer or regulator audit your data quality? There usually is a correlation between a bottleneck in the process and a bottleneck with the information (synonymously data). Using the 80/20 rule, your highest defective process usually has the highest information defects too, so start there.
- Once you have found the area with the highest data defect rate that is also affecting your process – find the source of the problem instead of continuing to clean or fix the information. Finding the source is usually a cross-functional problem which means IT will be involved. We must engage this cross-functional team to stop the data defects at the source.
- As part of the data quality sampling and audit program – we must test its fitness for use. Error or defects are obvious barriers to useful data, but there are other reasons it won’t be useful. For example, a missing key demographic that is significant not noise so you are unable to see granular enough to prove meaning in the existing data. This is one of the benefits of data governance and having a business glossary so everyone knows what is important to collect and more importantly, what is not important to collect (see above – data production problem).
- Go deep not wide – if you can’t tell, I love the 80/20 rule and what Jim Collins says in his book “Good to Great” and “The Enemy of the Great is the Good.” If you get one process to have great data – it is similar to when Roger Banister broke the 4-minute mile barrier – high school-aged kids do it routinely now. Go deep and make your data great and more will come. Unfortunately, the same holds true for not so great data, so decide wisely.
Now that we have better data what does that do for us?
- Builds Trust – Again, “In God we trust, everyone else brings ‘TRUSTED’ data” should be the new mantra.
- Saves Time – Just like lean processes reduce cycle time, so does lean data. If you know where your data are and what it is being used for, the time spent finding it and figuring out what to do with it is virtually zero.
- Automates Decisions – If driverless vehicles are the future, great data are required. This holds true for all decision automation opportunities like predictive analytics (Machine Learning/Artificial Intelligence).
- Reduces Fraud – The unintended consequence of data cleaning rulemaking is the ability to install bias. Who sponsors data analysis projects matters because most data are not fit for use so there will be data cleaning rules. The man with the gold makes the rules apply here so if your data are great that reduces the potential to install bias into the data!
I hope I made my case for great data and provided you with actionable steps to actively pursue it. “In God we trust, everyone else bring ‘TRUSTED’ data” needs to be our new mantra. We must do our part every day to demystify data and expose its quality.